ScreenMatcher (WIP / NOT PUBLIC / PLEASE DON'T SHARE)
ScreenMatcher is a thing (utility? service? daemon? background process? TSR?1) that you install that runs in the background of your Mac and watches your screen all the time.
You can teach it to detect and respond to anything that appears on your screen. Here's an example of a pattern you could tell ScreenMatcher to look for:
FIXME
And here are all the places it shows up on my screen:
FIXME
(podcast: https://museapp.com/podcast/73-folk-practices/)
(is this useful? i have no idea)
You set up ScreenMatcher by taking a 'screenshot' of whatever pattern you want it to detect. The interaction is almost exactly like when you take a normal screenshot.
So you install it, then run it, then
- you hit a keyboard shortcut (Cmd-Shift-1),
- then drag out a rectangle on your screen.
(TODO doc/ movie at smaller scale)
This teaches ScreenMatcher to look for that pattern on your screen from now on.
Let's have ScreenMatcher detect the [TRAFFIC LIGHT BUTTONS] in the top-left of every window.
[VIDEO FIGURE]
Now ScreenMatcher can see these traffic light buttons and call them out in the future, whenever it sees them.
[traffic light buttons]
[video of focusing different windows and seeing traffic light buttons]
example:
- match traffic light buttons -> draw extra button(?)
You can draw on top of the pattern, and ScreenMatcher will put that drawing wherever it sees the thing.
FIXME animation of drawing
You can draw on anything on your computer.
You can attach a script to any piece of graffiti.
You can put buttons on anything on your computer.
Model
patterns
you can draw on a pattern with various 'brushes':
FIXME screenshot of brushes
- match anything
- stretchy-match anything (this void can grow)
- match into colored variable
- & emit variable into here
How it's made
(you can probably skip this section, I just wanted to write it out)
Matching patterns
It took a surprising amount of work just to implement the mechanic of 'continuously scan the screen for these image patterns'.2
This mechanic is essentially implemented by 2D convolution, the same operation that's used in neural network stuff on images. You want to slide each pattern across the entire screen, checking every position on the screen, and then any hot spots are matches.
But there are a couple of details that make it surprisingly complicated:
-
The kernels are big: I don't know ML at all, but my understanding is that in machine learning, your kernel (the thing you're sliding) is usually gonna be, like, 3x3 pixels.
Our kernels here are a lot bigger -- even the window traffic lights are, like, 80x40 pixels. That's actually a lot more pixels. That's a lot more work you have to do at each screen position in your convolution, if you're doing the traditional spatial (literal sliding-across-the-screen) algorithm for convolution.
So you can't use the spatial algorithm; you can't use nice-sounding convolution functions like Apple
vDSP_imgfir; it's just way too slow. It's designed for those 3x3 or 5x5 or whatever kernels, not for giant kernels. It uses the naive algorithm ("it uses direct arithmetic and not an FFT implementation").If you want to convolve an 80x40 kernel, you need a different approach; you need to do the convolution in the frequency domain.

-
Normalization: You need to normalize the convolution -- convolution does multiplication, not matching per se. If you had a screen with a lot of white (high-intensity) spots, those white spots would show up as hotspots under ordinary non-normalized convolution; they'd become spurious matches. So you need to normalize by dividing by the mean value of each region you're matching.
It's not obvious how to efficiently do this if you're convolving in the frequency domain. There're a couple of papers about it that are cited by absolutely everyone: "Fast Normalized Cross-Correlation" by Lewis and "Template Matching using Fast Normalized Cross Correlation" by Briechle and Hanebeck. (The Briechle and Hanebeck paper is funny because everyone cites it, but they mostly cite it for its re-summarization of Lewis; I don't think I've seen anyone use the approximation that is actually the main contribution of the paper.)
Process
I guess that was sort of the algorithmic walkthrough. There's also a process walkthrough, which might be more honest3 -- I made a bunch of prototypes as I tried to get the interaction to work:
-
Lua + Hammerspoon: Getting the screen is easy here, and binding a global hotkey is pretty easy, but matching is hard. (you have to write a C FFI thing in a separate file and compile it to a shared library to do anything expensive or not-supported-by-Hammerspoon)
(I started on this because I like Hammerspoon for simpler tasks, I liked the idea that I could access a lot of system capabilities concisely and run in the background by default, and I don't like using Xcode if I can avoid it)
(I didn't get to this part on this prototype, but) I think it would also be hard on this tech stack to make the interactive GUI where you can see your list of patterns and select one and draw on top of it, and I think that drawing mechanic is a lot of what makes ScreenMatcher interesting.
(man, making GUIs is hard)
-
Pure Objective-C: I moved to a plain old Objective-C/AppKit app, in Xcode and everything. It's nice to be on the expected path for making a GUI. I tried writing my own matching algorithm that would iterate through the pixels at each point on the screen.
-
Objective-C + OpenCV: I only had a few days in the retreat, so I was like, I should probably use an off-the-shelf image matching library to prototype, even if it adds an ugly dependency to the system for now.4
There is one specific image matching routine that is literally the only function I needed from OpenCV:
matchTemplate5
-
Pure Objective-C (Apple Accelerate): I really didn't want to ship OpenCV with ScreenMatcher, and I wanted to know how the template matching worked, so I spent a long time after the retreat -- months -- reimplementing it as a single C file that only uses Apple native APIs.6
But Apple doesn't have
cv::matchTemplate(or the MATLAB equivalentnormxcorr2), so I needed to implement that logic ("normalized cross-correlation") in terms of Apple's more primitive math functions like FFT, pointwise multiplication, pointwise addition, etc.
-
Objective-C + Apple Accelerate + incremental matching: Incremental matching is the next obvious speedup.
FIXME
(it's funny, I describe these prototypes in terms of high-level technologies like Lua, Hammerspoon, AppKit, OpenCV, Apple Accelerate, but a lot of the experience on the ground is just banging my head around 2-3 very specific API calls in each system and trying to figure out if they exist or if they do the specific thing I want. other than the experience of writing the GUI, which was its own thing in a way.)
Performance thoughts
performance. incremental / diff based? won't it be really slow? won't it use a ton of battery? (link other continuous screenshot stuff. link patrickc thing?)
well, what if it isn't? let's assume it isn't slow, as a provocation. what could we do with it then? (Bret on learnable programming) if we want it to be fast or power-efficient, we'll spend money and make it fast and make it power-efficient, if it's worth it to us.
(examples of inherently expensive stuff: z-buffer stuff in GPUs. running JavaScript. network packet matching. TLB. you just have to do this stuff in hardware because it's so expensive otherwise and so important)
(maybe i don't really believe this for languages -- like i don't know if i really believe in JIT compilation -- but i do believe it for 'fixed functions' in some sense and this feels fixed enough)
battery measurement?
CV matching? opencv, cross-correlation, what
image compression annoying. can't do exact pixel match easily even if that's what you actually want
Making a paint app
Writing paint software is always a little annoying. You have to make this whole toolbox, you have to wire everything up, it's not a stereotypical GUI where you have buttons and state.
There's an interesting design question here, too -- what does a paint app for drawing screen-matchers look like? You don't really want users to draw arbitrary pixels on the pattern, because they're very unlikely to match. It's more like a sort of collage. Everything has to be cobbled from something that's already on the screen. (or be another sort of computational paint, like fuzzy-match or wildcard paint)
Tweets
- "Screenotate-ish daemon that's constantly doing light computer vision / text parsing on your screen for things you scripted it to care about"
- "it doesn't feel like you're automating your software, it feels
like you're automating this lifeless
skeleton
next to your software and you need to get this anatomy lesson of
what all the bones are before you can do anything"
- I think a lot of existing software automation/no-code/scripting things feel like this, regardless of whether they involve textual programming or drag and drop. they don't have the directness of working right off the running software on the screen
- "wonder how many pipe-oriented Unix tools you could reformulate as
screen-watching
applets" /
"applet that I can point at any number on my
screen and
it watches that number, detects how fast it's increasing, and gives
me a time estimate of when it'll finish"
- FIXME where's the redblobgames thing
- debugging tools past the edge of the screen
- how do you invoke tabfs? need a button
- the desire to have a global, reprogrammable hotkey that creates a space for reprogramming
- the desire to draw on apps / make notes on apps
- against recognition ipad
- (one answer to what it would mean)
- https://mobile.twitter.com/rsnous/status/1494186577823776770
- tcl but with images
- screenotate tcl
- unix native images
- https://twitter.com/rsnous/status/1295848842030510080 desire for wysiwyg programming / string literal but for gui
- tangentially related: "i'm doing this with my cursor, so i could teach the computer to do the same thing with its cursor"
Systems that I think about
-
"Windows Corner Thing" for Windows 3.1: you'll think this is kind of random, but I saw it and tried it when I was a kid and I keep thinking about it.

because the mechanism was so clear and so concrete: it was just a little window with the Windows 95 controls that would follow your active window around. you'd even see it move when you switched your active window -- it took a split-second to follow you, if I remember right. that's what ScreenMatcher feels like, too, and it doesn't need to be a bad thing
-
Prefab: extremely cool work, very similar in technology and in some high-level goals, more sophisticated in a lot of ways (it builds an actual UI tree that is queryable, it has actual principles of pattern-making).
but it doesn't have the same frontend interactions (drag out a pattern, draw on it), and I think the frontend interactions matter a lot and are a lot of the novelty in ScreenMatcher. Prefab is more of a programming toolkit than an end-user tool. it doesn't have that lightness, that directness
-
Sikuli & maybe(?) AutoHotKey (see also): these feel targeted at 'automation', not 'augmentation'. (doesn't Sikuli tie up your screen and I/O while it's running?)
i'm not really interested in making a robot that can type on my computer and click buttons. i just want a better computer for me, a human, and i want to create the feeling that i can always mess with it and tweak it on the fly
also, they are code-based tools, not direct-manipulation, even though they use similar implementation techniques to ScreenMatcher (i think Sikuli uses OpenCV, right?)
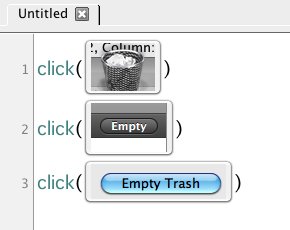
i do love the inline-screenshots-in-the-middle-of-code-editor aesthetic! maybe there is some nice synthesis possible here
-
Buttons: i really like this one; i feel like it might be the closest thing in spirit to ScreenMatcher, in how it creates a new, lightweight sense of how you can extend your computer (you can make a button, you can make a matcher and scribble something)
Buttons seemed to serve a stronger role than we expected in communicating between people with different programming skills. They are regularly distributed by email, but perhaps more interesting, it is not uncommon for someone to request “a button to do X”, where “X” may be something for which a button is quite definitely not the solution. We suspect that some of these requests would not be made at all if it were not possible to articuIate a putative solution in terms of something concrete and comprehensible such as a button.
and this extensibility doesn't require you to go into a programming mode -- you can make a button by tweaking an existing button, or by encapsulating system state
-
Scott Kim Viewpoint / Dynamicland (currently-held keys on outer edge of screen)
-
Shape Computer
-
the TAS split thing - doesn't let you move it around
-
my Screenotate: I had an idea to extend that was arguably one of the original inspirations that led to ScreenMatcher -- I was thinking about a version of Screenotate that would 1. steganographically embed the metadata in the screenshot itself and 2. continuously scan your screen for any of those screenshots with embedded metadata (e.g. that your friend sent you in a chat, or that you're seeing in your Twitter feed)
(idea to scan for screenshots you've taken?) (idea to use screenshots as links for office embedding?)
a screenshot-plus-embedded-metadata would almost become a kind of 'visual link' that is readable both to a human (as a screenshot) and to a computer (as navigable metadata of the origin URL/whatever of the screenshot), and you could send people that visual link over any service that accepts images (Twitter, iMessage, Facebook Messenger, Slack, ...), and if they had this augmented Screenotate, they could both see the screenshot and probe for the screenshot's origin
I also think that ScreenMatcher takes after Screenotate's spirit of respect for the 'folk practice' of just taking screenshots instead of using the 'correct' application-specific export or share or copy mechanism. that screenshot-taking gesture is still underrated, imo; it's so general and so trustworthy and so powerful. what if programming your computer could feel like that?
-
the way that Reddit Enhancement Suite let you stick tags on any Reddit username that you'd see on all of their posts from then on, just for your own information.
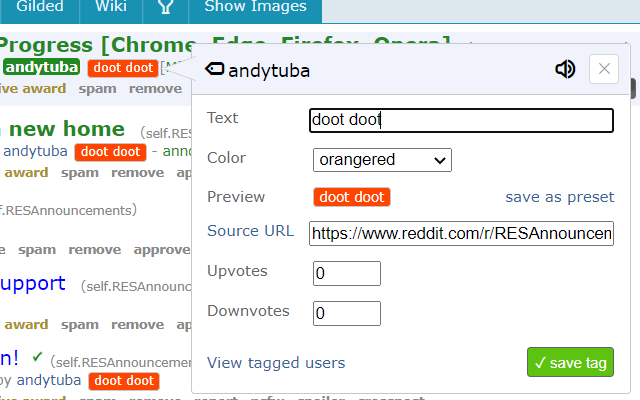
software that contains free space where you can just annotate whatever
-
ToonTalk: I haven't properly read this paper, but I saw it in Your Wish is My Command, and the compressed idea from it, that erasing detail is a way to create abstraction, has been stuck in my head ever since.
that's why erasing detail from a screen matcher pattern is a way to create a parameterized (abstracted) matcher.
-
HyperCard?
-
term rewriting / Japanese thing
-
Acme: (one flat space). (Oberon) instead of a uniform textual space, your computer is a uniform raster-image-space
-
the stupid etoys intersection thing / the dynamicland tripwire idea (what's-his-name? Patrick Dubroy?)
-
automated testing stuff
-
macOS Services via dj
-
painting with interactive pixels
-
Xerox Star retrospective: "When everything in a computer system is visible on the screen, the display becomes reality. Objects and actions can be understood purely in terms of their effects upon the display. This vastly simplifies understanding and reduces learning time." (we can take this much more literally)
-
"screenmatch" http://up.csail.mit.edu/other-pubs/chi2012-screenshots-for-translation-context.pdf continuously taking screenshots
-
"screenshot matcher"
-
Various 'daemons' that work universally on the computer:
- tip https://github.com/tanin47/tip
- replica
- other one i forget?
-
Devine's multiset rewriting https://wiki.xxiivv.com/site/pocket_rewriting.html
https://twitter.com/dubroy/status/1495766630927794180
- transductive regular expressions https://github.com/c0stya/trre -- this makes me wonder about a similar compact expression form for image rewriting
Stuff that would be interesting to do
- Block ads: FIXME screenshot of Promoted Tweet. stretchy?
- Add an extra traffic light button to windows:
- Add notes:
- Making guides for other people (the EUP Nardi thing + some other paper about guides that I forget)
- uuid contact photo
- tvtropes bullet point
- could you generalize screenotate?
- Timer that runs based on system clock in corner
- alarm clock
- data analysis, point at a plot on the screen, give me the original data, give me summary statistics, maybe i can reproject it into a new plot or detect if something is wrong, maybe i can ingest it into a new computation without needing to awkwardly 'save it to a file' or something
Dream: Map things in and out of screen-space
the screenshot could include the keyboard/mouse state like right off the edge of the screen
run code in arbitrary language / context of your screenshot drawing
Dream: Represent actions as images; nesting
this was an idea from the other week
things could output other things, and then a root matcher could do the action, instead of the action being that you type a bash script in
there's one space that is fully descriptive
this is kind of like Dynamicland
feelings
the lightness of the thing is so important. (do you remember this dream from TabFS, too?)
i think that i have a penchant for 'hacks' or 'tricks' that plug into your existing world, that involve objects that you already recognize and care about. (TODO search "care about") (on tabfs). it's not making up a new computational universe; it's just a half-step from where you are right now, on your actual computer on your desk (opposition to DL stuff?)
bridge between two worlds / bridge existing world / post-modernist.
tabfs script invocation
fpga idea / analogy to network hardware all this stuff -- this data -- flying through your computer would people actually use this? I don't know. it's like writing your own firewall rules
(maybe people would write their own firewall rules if they were constantly seeing network packets flow through their screen, right in front of their face. yoshiki link. my ports as bitmap idea)
ephemeral tools / jigs
frustration with 'if then then that' / AppleScript / automation being about picking the right thing out of finite list of things you can respond to. want smooth gestures, direct manipulation. want to point at the thing that i'm talking about, not find it in a list
dynamicland energy of 'the input / state of the computer is exactly the thing you see on the screen'
'object-oriented'. there is a sense in which you're 'subclassing' an object on your computer when you take a screenshot of it and draw on it (and maybe that's the platonic ideal form of this, like it's what should actually happen)
'against recognition' -- in a deep sense -- the idea that you could have a computer where images precede characters, where you think in terms of images. no text. just images
you're kinda like... why doesn't everything work this way. why isn't this built into the OS
i want you to feel what i feel, that there's something electric about this. i want you to find yourself saying, this is what the computer should be, that of course I can point at anything on my screen and use it as a scaffold or beachhead and reprogram it and attach behavior to it. this is my computer
Concepts
I'm always a little uncomfortable talking about concepts or principles beforehand. I'd rather feel like I'm just messing around.
But now that we have this system in hand, maybe we can look back and try to articulate the principles that made it feel interesting:
-
the imagistic computer. Tcl. Scott Kim
-
the constantly-reprogrammable computer. the hotkey
-
the computer that you can draw on. this feeling that you can paint with your finger, directly scribble on GUI surfaces, make them feel like they're owned by you and not by Apple
maybe also the feeling of painting with computational paint that is dynamic and alive and responsive. wouldn't you rather program your computer by doing that instead of writing code?
I was surprised by how compelling and distinctive people found this drawing gesture. From my point of view, it was just the easiest, most obvious thing to implement, but people are really attracted to this graffiti notion/interaction
-
programming not as 'software engineering', where a professional engineer comes up with the right design in their head and then executes it to create a product for consumers, but as an improvisational activity that everyone does, on the fly, with whatever parts happen to be at hand
your screen is this environment with all these flora and fauna, context, data already lying around.
symmetry where your computer sees the exact same 'channel' of data you do
(like pulling data in to program by example in the clause cards in DL).
-
direct manipulation. you drag stuff around (you want to see how fast it can keep up?) and it responds, distorting your movement in a way
The first prototype of ScreenMatcher was written at Gradient in February 2022 -- it was something I'd been meaning to do for years (not uncommon), and the retreat was the excuse I needed to break out of my normal routine and set of projects.
thanks to Avi for hosting and to Toph, andrew, Horace, and Robert for being around to bounce off!
TODO link people's projects / Twitters ?
TODO:
do differential screenshot grep so it's fastit shouldn't do anything in steady stateit ideally would smoothly follow when you drag stuff aroundit ideally wouldn't compound
garbage-collect processed images- cache FFT of all templates
- cache FFT setup
- you can probably just cache a few powers of two
- save templates to disk
- compile matchers to shaders outright?
TODO TODO:
- action brush creator (script->brush)
- match brush creator?
TODO speculative:
- different brushes (stretchy especially, maybe variable)
- cool brush effect like in the playdate physics video esp for script brush
- ocr brush
- brush with variable timing (every second, every 10 ms)? variable
match strength?
- continuous feed from match strength to opacity
- keyboard offscreen?
- automatic script action? effect pills?
- scoped matchers (based on window title). window title brush?
- kkwok-style synthesis of example matches ?
- live editing of match?
- uuid / 'fresh' maker so you can use screen matcher to create 'figures' / 'overlays' on arbitrary stuff
- configurable match threshold? configurable match resolution? configurable match rate?
- downscale with FIR low-pass filter?
- screen cap w/o compression?
- graphical find and replace
- it's fun because it's direct-manipulation, your motions directly impact it
- fpga coprocessor
- geiger
- use the extra color (wide color gamut) like Apple Intelligence
FIX:
- the grayscale conversion is way too destructive (the images are too dim/low-contrast); this might also be why decimation isn't working well
- monitor perf in tracy/instruments
- signpost each detection
- (we are spending most of our time on the summed area table, not fftconvolve)
- make it one-click to draw?
already works on win/lin via vnc
in a way, you should take it as an indictment of your computer that this works. it's so regular, so dead, so static -- and this is exactly what we exploit7
-
exactly the kind of thing you can't do in a Web page or a smartphone app, where those platforms limit your imagination and the domain you can work over ↩︎
-
It's not that obvious that it's worth implementing, because it seems so inefficient and wasteful and indirect to actually pixel-match stuff on the screen. so maybe a lot of people wouldn't make this leap, given how much work it is to try?
like, wouldn't it be better to match the actual UI views, or match the accessibility tree, or even build your own UI tree so you don't have to constantly pixel-match, or something? doesn't that feel more right?
but I think the concreteness and generality of pixels is a lot of why it's interesting :-) and I'd been interested in it for so long that it was inevitable that I'd eventually try it ↩︎
-
it was only after step 3, when I had the interaction working, that I walked back and was like, ok, I know this is interesting and I want to ship this, now how does it work, what computation is this thing actually doing, how can I speed it up and implement it without the CV dependency ↩︎
-
It's strange that OpenCV is kind of the only option I could find for this? Image matching function that you can call from a C program (as opposed to being in SciPy or Matlab or something) ↩︎
-
well, the OpenCV routines to draw arbitrary images on the screen and annotate them are also very useful for debugging ↩︎
-
Apple has a pretty good math library, Accelerate, that seems very fast and doesn't require any external dependencies, and I'm only targeting macOS with this software anyway. ↩︎
-
 ↩︎
↩︎